宁波象山石浦——建议大力发展旅游业或者直接关闭
说走就走的旅行并不总是美妙的,它更可能充满着艰辛与消极意义上的意外——这次去宁波象山石浦的旅行便印证了这一点。
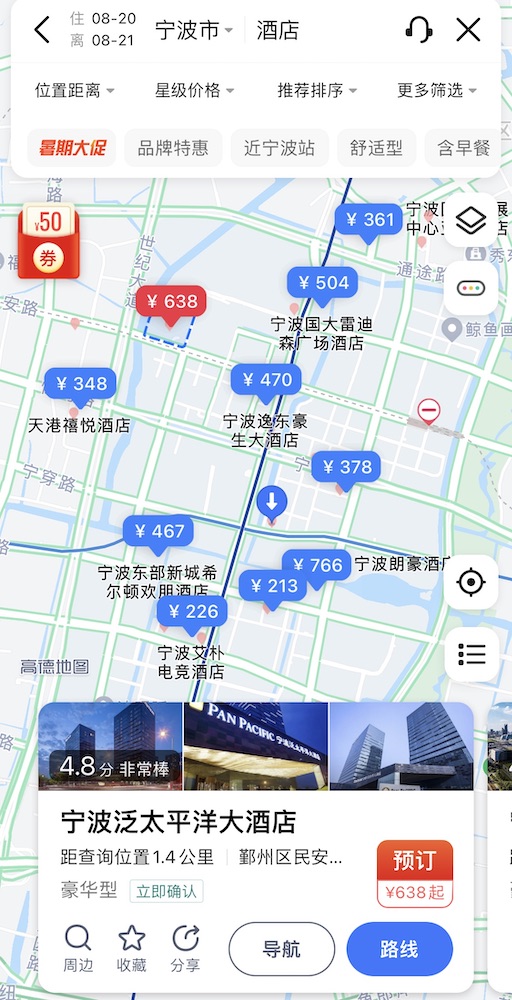
其实回过头来想想,前几天找旅馆的情况就应该是一个预兆,应该有充足的心理预期——这个十八线县城的旅馆房价不能说是世界最贵,但性价比可能是宇宙最低?并且提前几天还订不到,订到了也被房东取消(两次),而前日却又空出不少,这是太贵了没卖出去降价吗?
- 15 平米交通不便的标间一天 500 RMB~1000 RMB。
- 60 平米大豪斯一天 3000 RMB 起,80 平米的一天 4800 RMB起。
本文先吐槽,后给出景点照片。
吐槽为先
石浦镇
关于交通
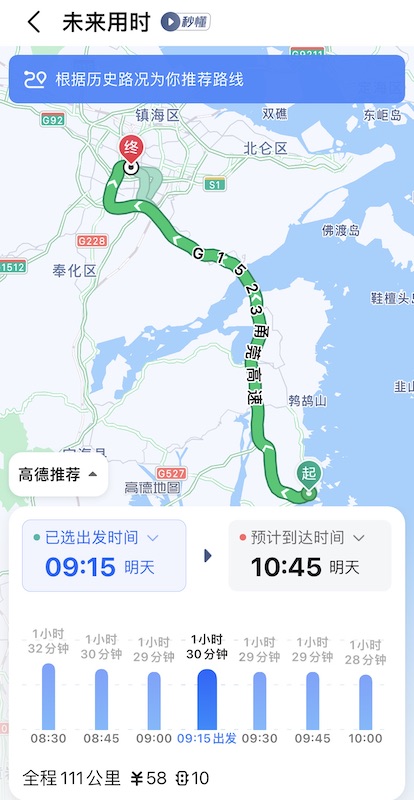
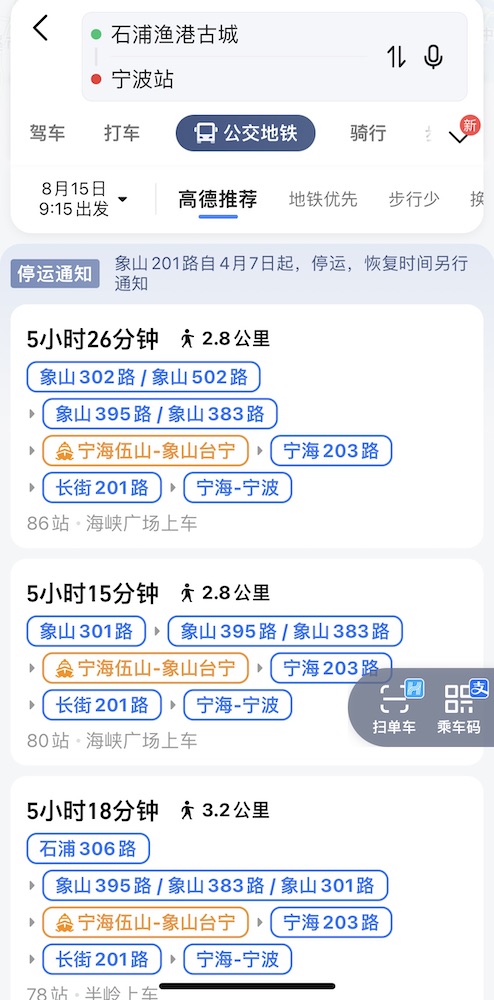
从宁波去石浦镇,120 km 的路程,公交是极慢的,还好打车没那么难打。
![alt 不就 120 km 吗]()
![alt 这公交能用吗]()
![alt 只好打车]()
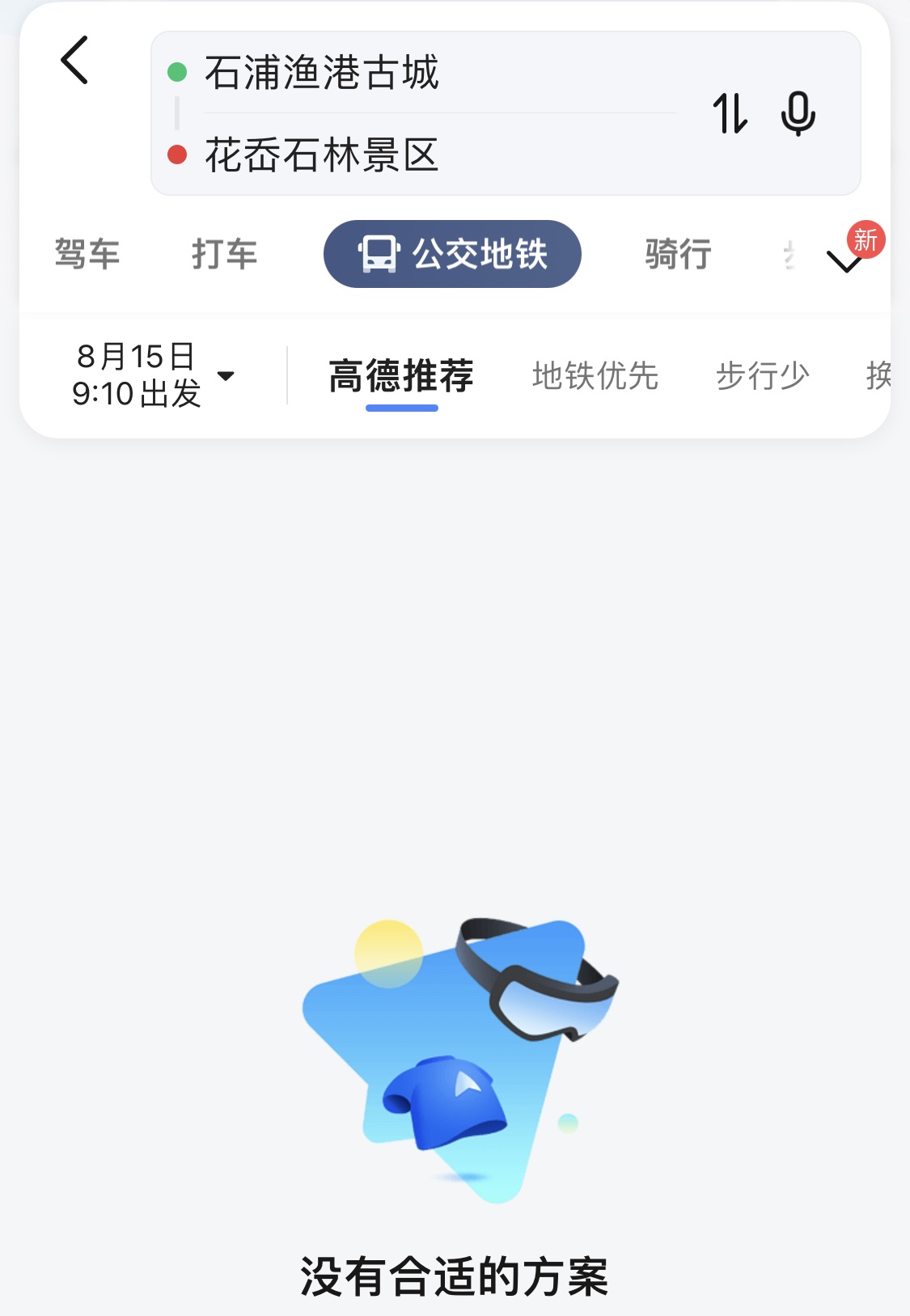
镇子里是没有共享单车、电动车的,去景点的公交基本等于没有。
看日出必须包车,而夜里 4 点是打不到去海滩(看日出)的网约车的,只能提前约好司机让司机单独送。(单趟 100 RMB 就 100 RMB 吧——可也没跟我说看日出的地方离住处只有3.6km。)
看完日出 6 点多也是打不到车的,时间也不算太早,地点也不算偏,加了 20 的红包也打不到。
檀头山岛的船双休日说停就停了。
渔山岛的轮渡一天一趟也没票的。
最后大概只能去花岙岛。而花岙岛是没有公交的,又得包车,一小时 100+ RMB,全程 500+ RMB。
去花岙岛还需要轮渡:5 分钟 2 km不到的轮渡一辆车往返 70 RMB 起步。
单人不开车不知道要多少钱。但是不带车过了轮渡就得回来,因为岛上没有任何公共交通工具,而从轮渡到景区的路得走 2 小时。所以不是包车就是没办法去。
![alt 完全没有公交]()
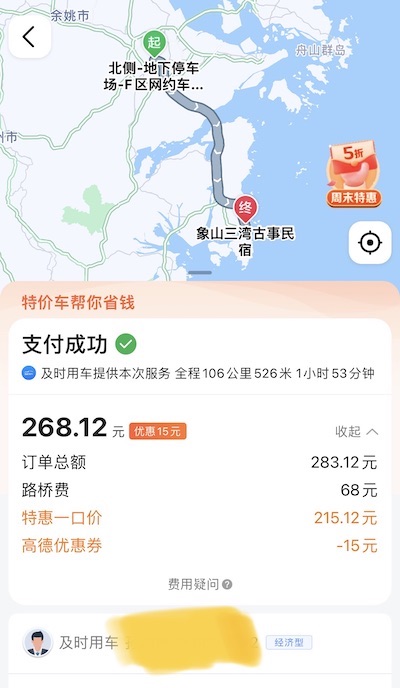
关于住宿:
- 周末价格变成平时的2~3倍,锦江之星快与张家界的希尔顿同价,有浴巾不跑蟑螂的民宿 500 RMB 起步,好一个宇宙中心。妈的,2021 年国庆黄金周,上海陆家嘴的汉庭标准间不也就 155 RMB 一晚上吗?
- 住的民宿里的双孔插座只有 2 / 5 能插进去。
- 住的民宿只准备了一双拖鞋。
- 好在房间干净,老板娘热情,提供了不少有用的情报。
关于吃饭:
- 店里的海鲜也都不便宜,吃了一顿“便宜实惠”的“开心小炒”,结果梭子蟹+小黄鱼+(卖不出去的)鲳鱼+香螺=420 RMB。后来得知想便宜就只能去菜市场自己买来然后找店加工(价格变成1/2~1/3)。菜场下午会有当日捞上来的新鲜货。
其他:
- 一位网约车司机不按导航走,开到了一个反方向的核酸检测点。看他提供了吃海鲜的情报,就当无事发生了。(吃海鲜的情报:海鲜市场里买完海鲜后,可以就地吃掉——卖鱼的附近有几家店,可以找它们代加工海鲜,根据做法,大概是 10 元 或 15 元一样菜。8 月的海鲜有梭子蟹,吊带,红头虾,滑饼虾,鲳鱼等。备注:下午去会有当天捞上来的梭子蟹。)
石浦半边山景景区
关于交通
离石浦镇中心景区(石浦渔港)不过 9 km,却没有公交,或者说公交下车要走 3 km,只能打车。
![alt 半边山的公交]()
从那儿出去的话打车也打不到,拼车拼不到。
去影视城,最后是加了 20 RMB 红包,20 RMB 调度费,等了半小时,总算有出租车接。
去景区,周围的一些道路是被封上的,这点就连神通广大的高德都不知道。
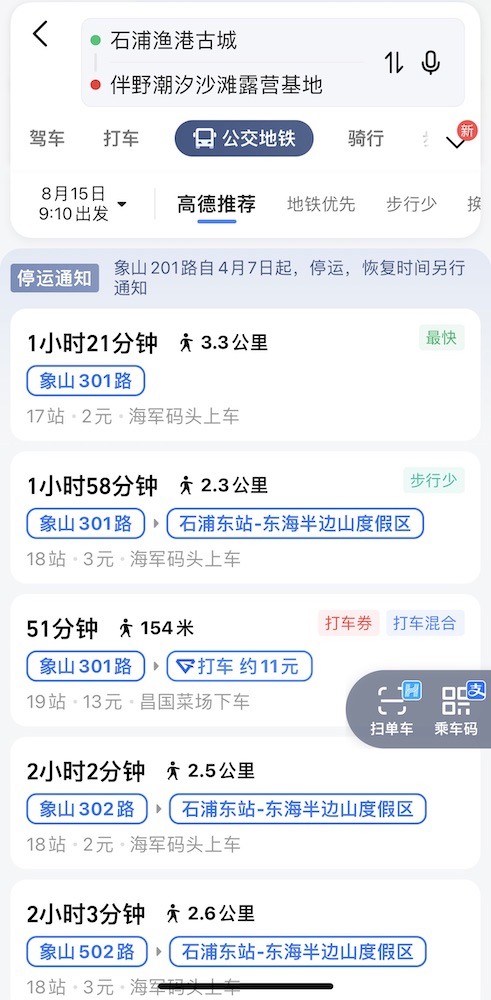
关于住宿
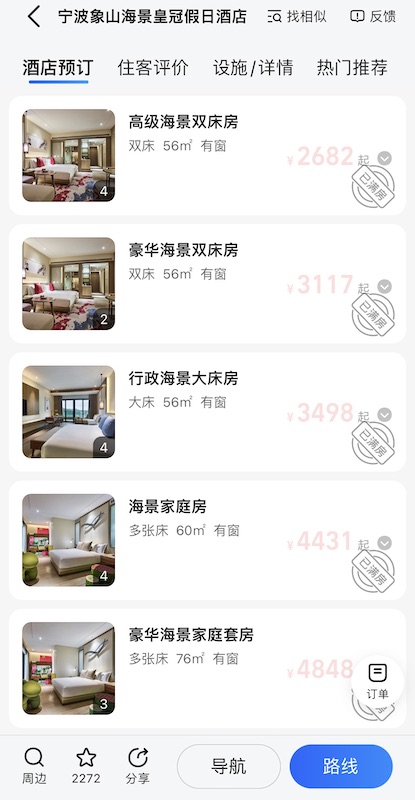
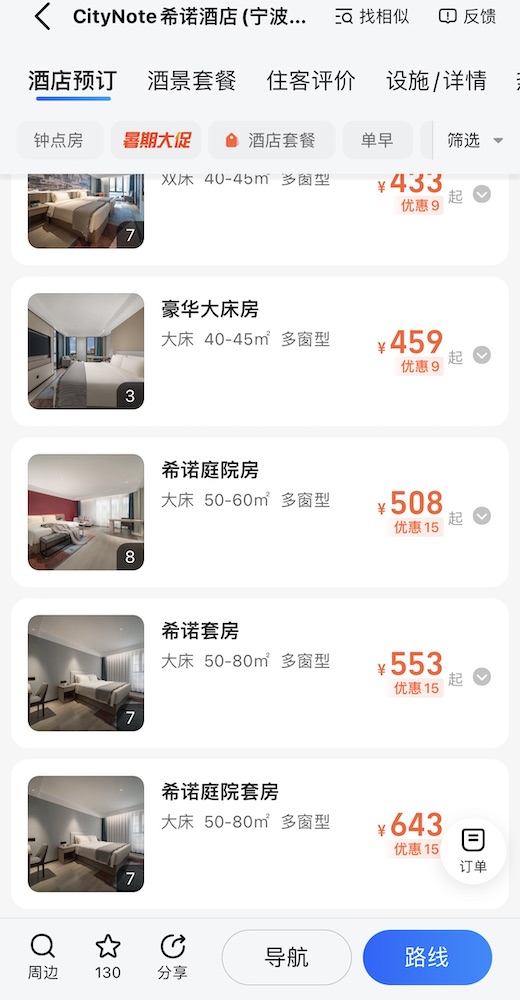
旁边的什么酒店,80 平不到的房间敢收 4800 RMB 一天的房费,也是佩服。
![alt 看这房价,里面是有黄金吗]()
![alt 看这房价,里面是有黄金吗]()
周围一片运作不规范 15 平米一间的民宿,也是 500 RMB 起步,1000 RMB 常规操作,不知道在想什么。
500 RMB 的民宿没有吹风机,没有浴巾,毛巾是有小片黑点的。
矿泉水是没有的(前面的民宿也没有,楼下也没卖的),隔音是极差的。
洗浴用品是过期三年的。
![alt 生产日期]()
![alt 保质期]()
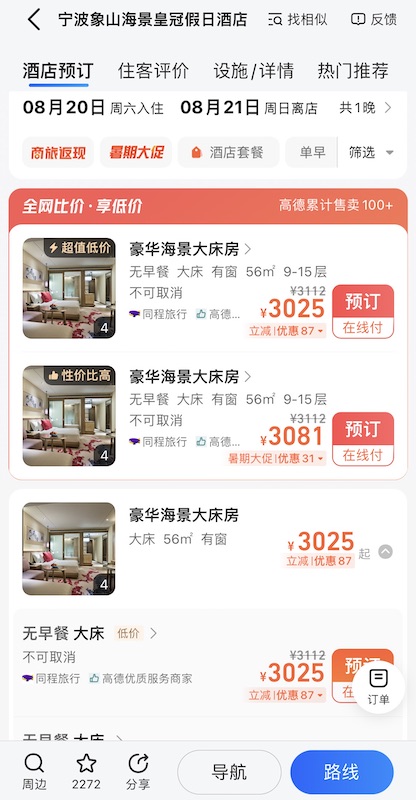


我就想问,宁波的房价和地段是不配吗?宁波的五星级的定价就只能是你石浦酒店的一个零头?
景区还有人拿个喇叭在岸边卖东西的地方喊“不要下水游泳,回来”,耳朵都聋了,好像一百米开外的海里能听到似的。
象山影视城
- 门票 150 RMB。昂贵的门票与实际可活动范围形成了鲜明的对比。
- 上海、民国景区不是没建好就是拍剧中不让进。
- 桃园行宫、泼水节那啥地方拍剧中不让进。
- 战国那啥旮旯地方也不让进。我问为什么,又说是在拍剧中咯,又说是 🐎 受惊很危险咯。我问哪来的 🐎?又说是剧组的咯。剧组的?那我问是不是剧组走了就可以进咯,也没问出个所以然。反正只能坐连轨道都没有的所谓的“小火车”。绕了一圈,感觉像叙利亚村子战场,啥也没看到,包括容易受惊吓的马。下了火车,前面的乘客也骂骂咧咧什么狗屁玩意咯。华为东莞的有轨道的小火车和建筑比它高不知道哪里去了。
- 水帘洞那啥地方拍剧中不让进。
- 唐城那地方不知道是没建好还是不让进。
- 山里码头那地方没建好……
- 实际上能游玩的地方几乎就只有归云庄、襄阳景区。
你™里面大部分地方不是没建好就是不能去,凭什么收 150 RMB的门票钱?真就又当又立不想要回头客?交通也基本等于没有,去城里的车每天只有 2 班。赶车就看不了傍晚、晚上的部分(古战场晚上才有,泼在节是第一班车之后)。全区还真就一个出入口,笑死个人。
从镇上最核心地带到景区,21 km 半小时车程,你让我公交 2 小时还要在 41 度的天下再走 2 km?
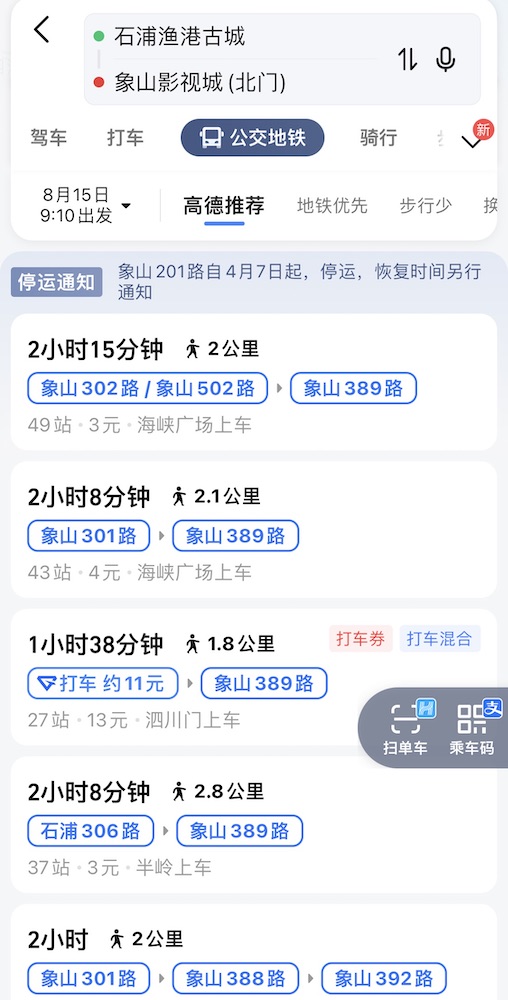
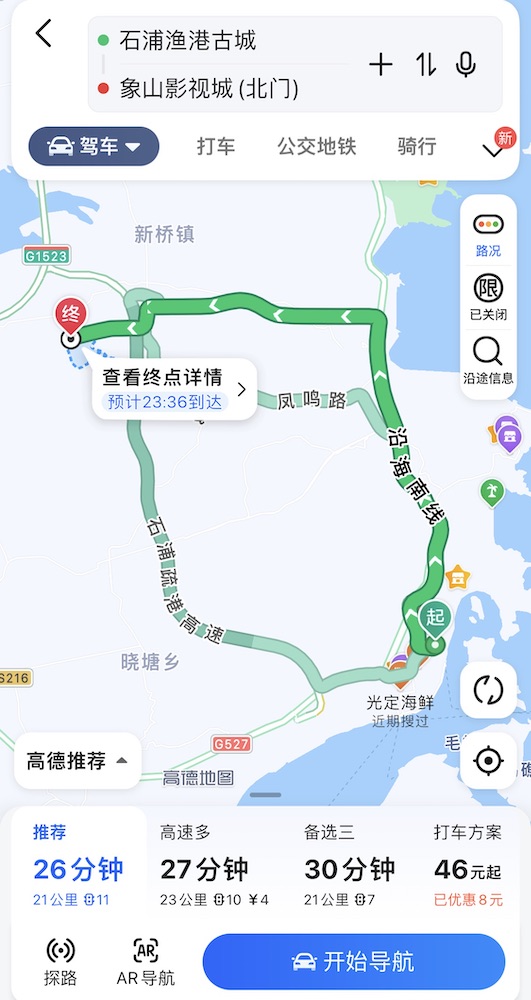
我们再看看从影视城回宁波的公交,1 小时 16 分钟的车程,换成公交就能给人整出来 6 小时 + 5 km 步行。
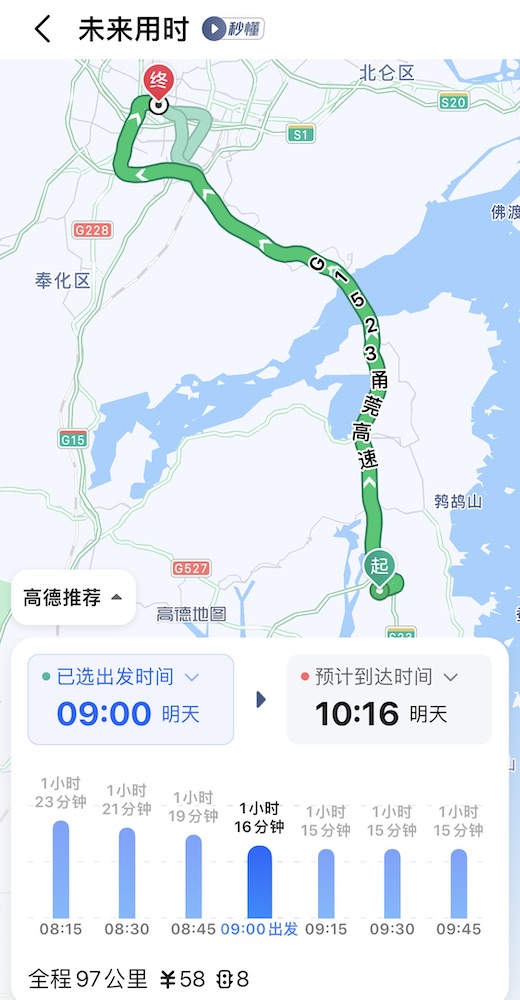
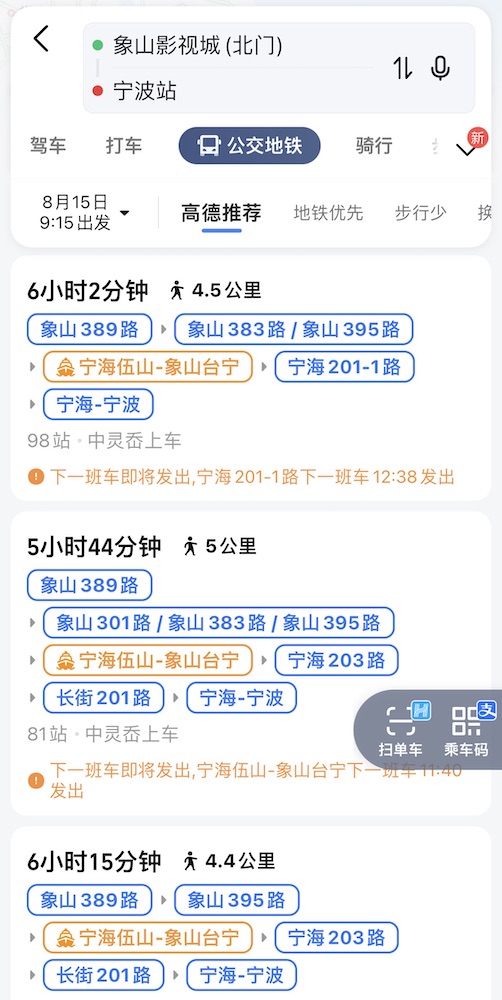
我只能说佩服,用这个姿势发展旅游业?甘拜下风!
好在最后打到车了,再见吧您。没下次了。
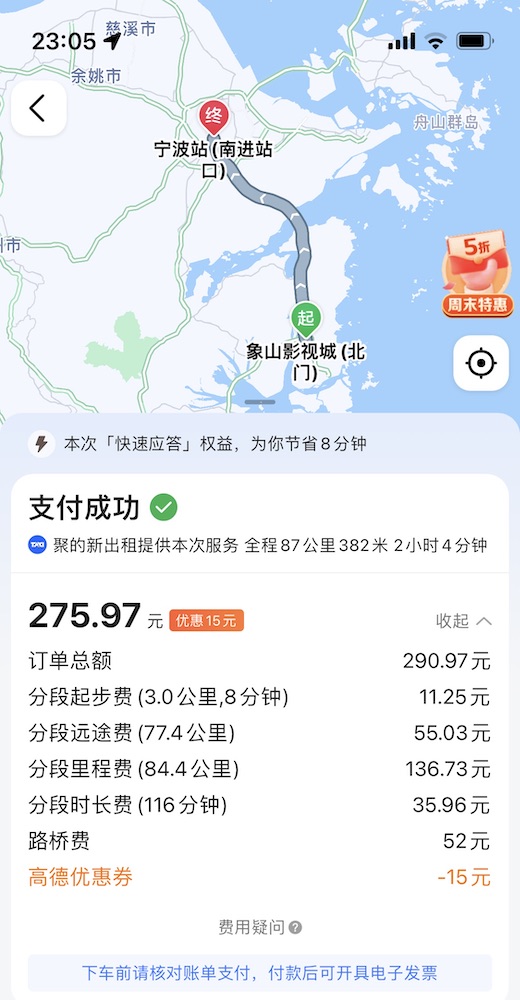
宁波站
- 男厕所灯少,很暗。冲水是自动的,但是坏了,所以脏。门也基本坏了,很难插上。洗手池的小到可以忽略。
- 我用的第一个自动贩卖机坏了,买了水后无法取不出来,近似于踹了一脚才拿出来。(难怪水比较凉。)
好的地方
心情极差的时候,似乎好的地方也不多了……
看日出挺好的,因为人不是很多,可以欣赏日出全景。天文奇观:以云朵为分隔,云朵之上的太阳,相比于云朵之下的太阳,又小又亮。
夜里月亮又大又亮又圆(农历七月十五),星星也很多。日出时日月同在。
宁波站进站查核酸、健康码的地方有遮阳篷(但还是很热)。宁波站自动贩卖机比较多,可以说是很密。
影视城里的襄阳城的布景和活动还不错。
有孙悟空大战蝎子精的皮影戏。
有个魔术比较精彩,手法是真的快。
能看到鼠戏。
有看手相算命的。
有鬼屋。